Blackbox AI ist eine VS Code-Erweiterung für KI-gestützte Codierungsunterstützung. Sie unterstützt benutzerdefinierte OpenAI-kompatible API-Provider und ermöglicht die Verbindung mit Infercoms EU-souveräner Inferenz-Plattform.
Einrichtungszeit: ~2 Minuten
Voraussetzungen
Konfiguration
Schritt 1: Blackbox-Einstellungen öffnen
- Öffnen Sie VS Code
- Klicken Sie auf das Blackbox AI-Symbol in der Seitenleiste
- Klicken Sie auf Einstellungen (Zahnradsymbol) oben rechts im Blackbox-Panel
Schritt 2: API-Provider konfigurieren
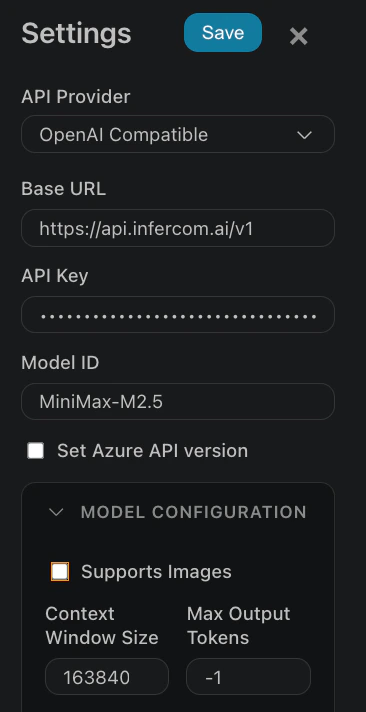
Geben Sie im Einstellungsdialog ein:
| Feld | Wert |
|---|
| API Provider | OpenAI Compatible |
| Base URL | https://api.infercom.ai/v1 |
| API Key | Ihr Infercom API-Schlüssel |
| Model ID | MiniMax-M2.7 |
Schritt 3: Modelleinstellungen konfigurieren
Erweitern Sie MODEL CONFIGURATION und setzen Sie:
| Feld | Wert |
|---|
| Supports Images | Deaktiviert |
| Context Window Size | 192000 |
| Max Output Tokens | -1 (unbegrenzt) |
Schritt 4: Speichern
Klicken Sie auf Save, um die Konfiguration anzuwenden.
Modell
Verwenden Sie MiniMax-M2.7 - optimiert für agentisches Coding mit 192K Kontext.
| Metrik | Wert |
|---|
| SWE-bench | 75,8% |
| Kontextfenster | 192K Token |
| Durchsatz | 400+ Token/Sek |
| Reasoning | Integriert |
Überprüfung
Testen Sie nach der Einrichtung mit einer einfachen Anfrage:
Schreibe eine Python-Funktion, die prüft, ob eine Zahl eine Primzahl ist
Fehlerbehebung
”Invalid API Key”-Fehler
- Überprüfen Sie Ihren API-Schlüssel unter cloud.infercom.ai
- Stellen Sie sicher, dass keine zusätzlichen Leerzeichen im API-Schlüssel-Feld sind
”Model not found”-Fehler
- Prüfen Sie, ob die Model-ID exakt
MiniMax-M2.7 lautet (Groß-/Kleinschreibung beachten)
- Verfügbare Modelle überprüfen:
curl https://api.infercom.ai/v1/models
Langsame Antworten
- Überprüfen Sie Ihre Internetverbindung
- Die Infercom API wird in der EU (München) gehostet - Latenz kann je nach Standort variieren
- Die erste Anfrage kann aufgrund des Modell-Ladens langsamer sein
Nächste Schritte